Last year the Internet got its first taste of image-generating artificial intelligence. Suddenly, technology that had once been offered only to specialists was available to anyone with a web connection. The enthusiasm shows no signs of abating, and AI-generated images have won a major photography competition, created the title credits of a television series and tricked people into believing the pope stepped out in a fashionable puffer coat. Yet critics have noted how training the algorithms on existing works could potentially infringe on copyright, and using them could put artists' jobs in jeopardy. Generative AI also risks supercharging fake news: the pope coat was fun, but a generated photograph supposedly showing an attack on the Pentagon briefly inspired a dip in the stock market.
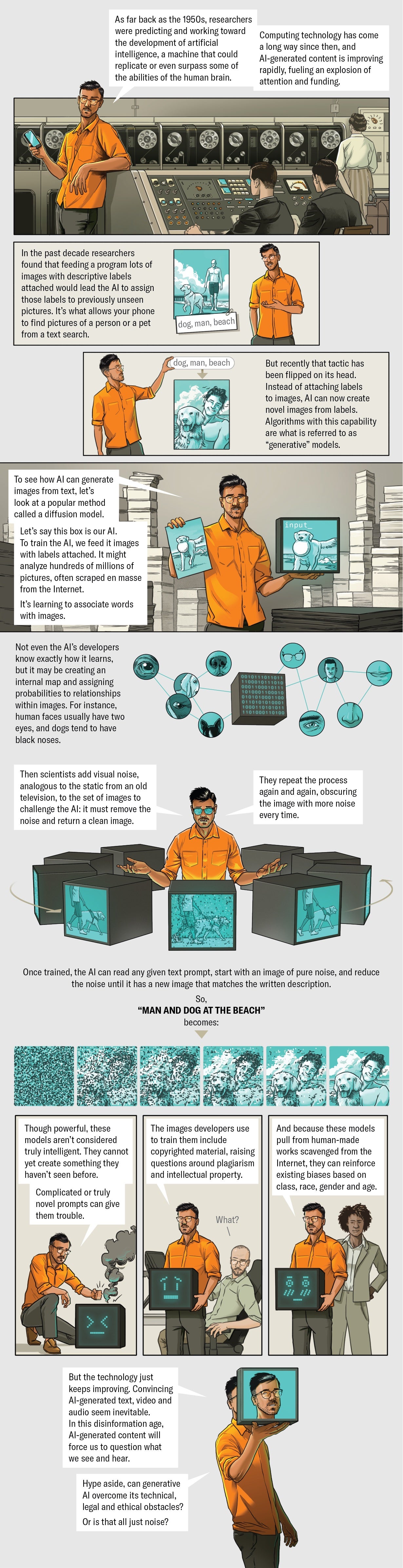
How did programs such as DALL-E 2, Midjourney and Stable Diffusion get to be so good all at once? Although AI has been in development for decades, the most popular of today's image generators use a technique called a diffusion model, which is relatively new on the AI scene. Here's how it works: